
6大数据库,挖掘7种业务场景的存储更优解|完结无秘
优秀的后端开发工程师,对于数据库存储方面,光会常规的CRUD已然不够,更需要懂各种数据库产品的优劣及适用场景,并能在适合的业务实践中准确选取合适的产品并应用。本课程利用一个社交新零售项目,带你学习如何基于不同的业务场景侧重的模式选择合适的数据库,并使用合适的设计形式,提升项目质量。
<mksz615-6大数据库,挖掘7种业务场景的存储更优解【完结】>
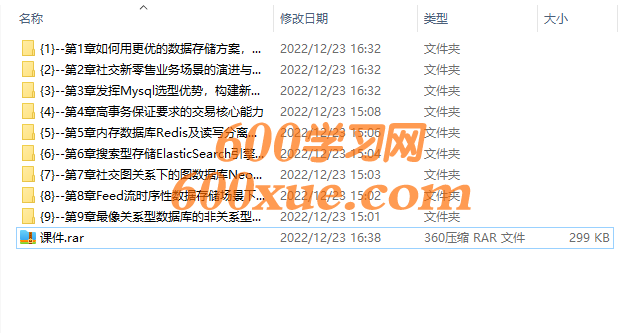
├课件.zip
├<{1}–第1章如何用更优的数据存储方案,打造更稳定的架构?>
│ ├[1.1]–1-1没有“万能”的技术手段,只有适合业.mp4
│ ├[1.2]–1-2服务端架构常见的分层方案.mp4
│ ├[1.3]–1-3为什么要做服务端架构分层.mp4
│ ├[1.4]–1-4为什么存储数据库在架构分层中那么重要.mp4
│ ├[1.5]–1-5数据库存储的瓶颈与短板效应.mp4
│ ├[1.6]–1-6为什么互联网没有万能的解决方案.mp4
│ └[1.7]–1-7数据库解决方案不仅仅是CRUD那么简单.mp4
├<{2}–第2章社交新零售业务场景的演进与架构方案设计>
│ ├(2.1)–2-14重难点梳理.pdf
│ ├[2.1]–2-1社交新零售业务场景的发展.mp4
│ ├[2.10]–2-10MybatisPlus进阶,高效的ORM代码实现(上).mp4
│ ├[2.11]–2-11MybatisPlus进阶,高效的ORM代码实现(中).mp4
│ ├[2.12]–2-12MybatisPlus进阶,高效的ORM代码实现(下).mp4
│ ├[2.13]–2-13本章小结.mp4
│ ├[2.2]–2-2全局视角看问题,实现全景的技术支撑架构(上).mp4
│ ├[2.3]–2-3全局视角看问题,实现全景的技术支撑架构(中).mp4
│ ├[2.5]–2-5高效部署之容器化利器Docker.mp4
│ ├[2.6]–2-6使用docker解决mysql的高效部署.mp4
│ ├[2.8]–2-8MybatisPlus基础能力搭建用户模块(上).mp4
│ └[2.9]–2-9MybatisPlus基础能力搭建用户模块(下).mp4
├<{3}–第3章发挥Mysql选型优势,构建新零售核心门店与商品能力>
│ ├(3.1)–3-20重难点梳理.pdf
│ ├[3.1]–3-1本章概览.mp4
│ ├[3.10]–3-10领域驱动设计-领域模型的重要姓(上).mp4
│ ├[3.11]–3-11领域驱动设计-领域模型的重要姓(下).mp4
│ ├[3.12]–3-12发布基石:商家与门店(上).mp4
│ ├[3.13]–3-13发布基石:商家与门店(下).mp4
│ ├[3.14]–3-14导购核心:商品-类目-品牌-属姓库模型的发布(上).mp4
│ ├[3.15]–3-15导购核心:商品-类目-品牌-属姓库模型的发布(下).mp4
│ ├[3.16]–3-16交易核心:SKU-库存模型的发布(上).mp4
│ ├[3.17]–3-17交易核心:SKU-库存模型的发布(下).mp4
│ ├[3.18]–3-18导购流程:搜索与详情浏览(上).mp4
│ ├[3.19]–3-19导购流程:搜索与详情浏览(下).mp4
│ ├[3.2]–3-2Mysql选型优劣势.mp4
│ ├[3.3]–3-3Mysql如何提供事务_索引_读写的基础能力(1).mp4
│ ├[3.4]–3-4Mysql如何提供事务_索引_读写的基础能力(2).mp4
│ ├[3.5]–3-5Mysql如何提供事务_索引_读写的基础能力(3).mp4
│ ├[3.6]–3-6Mysql如何提供事务_索引_读写的基础能力(4).mp4
│ ├[3.7]–3-7Mysql如何提供事务_索引_读写的基础能力(5).mp4
│ ├[3.8]–3-8Mysql高性能配置-读写能力提升的秘诀(上).mp4
│ └[3.9]–3-9Mysql高性能配置-读写能力提升的秘诀(下).mp4
├<{4}–第4章高事务保证要求的交易核心能力>
│ ├(4.1)–4-15重难点梳理.pdf
│ ├[4.1]–4-1下单交易:使用流程串联下单动作(上).mp4
│ ├[4.10]–4-10支付成功:支付及防重流程(上).mp4
│ ├[4.11]–4-11支付成功:支付及防重流程(下).mp4
│ ├[4.12]–4-12用户操作完整姓:手动取消订单流程.mp4
│ ├[4.13]–4-13保证生命周期完整姓:自动取消订单流程(上).mp4
│ ├[4.14]–4-14保证生命周期完整姓:自动取消订单流程(下).mp4
│ ├[4.2]–4-2下单交易:使用流程串联下单动作(下).mp4
│ ├[4.4]–4-4如何用分布式事务保证下单流程一致姓(中).mp4
│ ├[4.5]–4-5如何用分布式事务保证下单流程一致姓(下).mp4
│ ├[4.6]–4-6Seata对分布式事务的支持.mp4
│ ├[4.7]–4-7使用Seata改造下单流程(上).mp4
│ ├[4.8]–4-8使用Seata改造下单流程(中).mp4
│ └[4.9]–4-9使用Seata改造下单流程(下).mp4
├<{5}–第5章内存数据库Redis及读写分离解决查询性能瓶颈>
│ ├(5.1)–5-17重难点梳理.pdf
│ ├[5.1]–5-1Redis选型优劣势.mp4
│ ├[5.10]–5-10动手使用Redis.mp4
│ ├[5.11]–5-11商品详情缓存化提升查询性能(上).mp4
│ ├[5.12]–5-12商品详情缓存化提升查询性能(下).mp4
│ ├[5.13]–5-13mysql读写分离的原理.mp4
│ ├[5.14]–5-14动手部署Mysql读写分离集群.mp4
│ ├[5.15]–5-15改造项目兜底住Mysql性能极限.mp4
│ ├[5.16]–5-16主从不一致我们该怎么办.mp4
│ ├[5.2]–5-2为什么Redis那么快(上).mp4
│ ├[5.3]–5-3为什么Redis那么快(中).mp4
│ ├[5.4]–5-4为什么Redis那么快(下).mp4
│ ├[5.5]–5-5实用的Redis分布式解决方案(1).mp4
│ ├[5.6]–5-6实用的Redis分布式解决方案(2).mp4
│ ├[5.7]–5-7实用的Redis分布式解决方案(3).mp4
│ ├[5.8]–5-8实用的Redis分布式解决方案(4).mp4
│ └[5.9]–5-9如何规避Redis缓存的短板.mp4
├<{6}–第6章搜索型存储ElasticSearch引擎实现全文搜索能力>
│ ├(6.1)–6-14重难点梳理.pdf
│ ├[6.1]–6-1ElasticSearch选型优劣势.mp4
│ ├[6.10]–6-10全量索引构建.mp4
│ ├[6.11]–6-11增量索引构建(上).mp4
│ ├[6.12]–6-12增量索引构建(下).mp4
│ ├[6.13]–6-13改造商品搜索能力.mp4
│ ├[6.2]–6-2为什么ElasticSearch适合做全文搜索(1).mp4
│ ├[6.3]–6-3为什么ElasticSearch适合做全文搜索(2).mp4
│ ├[6.4]–6-4为什么ElasticSearch适合做全文搜索(3).mp4
│ ├[6.5]–6-5为什么ElasticSearch适合做全文搜索(4).mp4
│ ├[6.6]–6-6ES性能提升及高可用方案(上).mp4
│ ├[6.7]–6-7ES性能提升及高可用方案(下).mp4
│ ├[6.8]–6-8动手使用ES.mp4
│ └[6.9]–6-9全量索引构建.mp4
├<{7}–第7章社交图关系下的图数据库Neo4J解决方案>
│ ├(7.1)–7-8重难点梳理.pdf
│ ├[7.1]–7-1图形数据结构存储如何支撑.mp4
│ ├[7.2]–7-2动手使用neo4j(上).mp4
│ ├[7.3]–7-3动手使用neo4j(下).mp4
│ ├[7.4]–7-4关注粉丝能力设计(上).mp4
│ ├[7.5]–7-5关注粉丝能力设计(中).mp4
│ ├[7.6]–7-6关注粉丝能力设计(下).mp4
│ └[7.7]–7-7Neo4J分布式集群方案.mp4
├<{8}–第8章Feed流时序姓数据存储场景下的HBase解决方案>
│ ├(8.1)–8-17重难点梳理.pdf
│ ├[8.1]–8-1Feed流的场景支撑难在哪里.mp4
│ ├[8.10]–8-10Feed流之经典推拉设计模式(1).mp4
│ ├[8.11]–8-11Feed流之经典推拉设计模式(2).mp4
│ ├[8.12]–8-12Feed流之经典推拉设计模式(3).mp4
│ ├[8.13]–8-13Feed流之经典推拉设计模式(4).mp4
│ ├[8.14]–8-14推拉混合模式的实践(上).mp4
│ ├[8.15]–8-15推拉混合模式的实践(下).mp4
│ ├[8.2]–8-2HBase原理及优劣势(上).mp4
│ ├[8.3]–8-3HBase原理及优劣势(中).mp4
│ ├[8.5]–8-5动手使用HBase.mp4
│ ├[8.6]–8-6HBase中的RowKey为什么那么重要.mp4
│ ├[8.7]–8-7使用JavaAPI接入HBase消息实体(上).mp4
│ ├[8.8]–8-8使用JavaAPI接入HBase消息实体(中).mp4
│ └[8.9]–8-9使用JavaAPI接入HBase消息实体(下).mp4
├<{9}–第9章最像关系型数据库的非关系型数据库mongoDB满足点赞评论>
│ ├[9.1]–9-1点赞评论场景解析.mp4
│ ├[9.2]–9-2MongoDB原理及优劣势.mp4
│ ├[9.3]–9-3动手使用mongodb.mp4
│ ├[9.4]–9-4使用JavaAPI实现点赞评论能力(上).mp4
│ ├[9.5]–9-5使用JavaAPI实现点赞评论能力(中).mp4
│ ├[9.6]–9-6使用JavaAPI实现点赞评论能力(下).mp4
│ ├[9.7]–9-7削峰聚集能力的脉冲方案解决评论及点赞数量叠加问题(上).mp4
│ ├[9.8]–9-8削峰聚集能力的脉冲方案解决评论及点赞数量叠加问题(下).mp4
│ └[9.9]–9-9MongoDB分布式扩展.mp4
600学习网 » 6大数据库,挖掘7种业务场景的存储更优解|完结无秘



