
驾驶员嗜睡分类 – 深度学习-600学习网
600学习网终身会员188,所有资源无秘无压缩-购买会员
瞌睡检测是一项车辆安全技术,它有助于防止驾驶员在驾驶时睡着引起的事故。根据国家公路交通安全管理局(NHTSA)的数据,警方报告的91000起事故涉及疲劳驾驶。2017年,这些事故导致约50000人受伤,近800人斯亡。目前,该方法主要集中于使用深度学习或机器学习技术进行眨眼检测,但如果司机戴着太阳镜怎么办?
如果我们同时考虑司机的头倾斜.打哈欠和其他因素会怎么样?是的,这正是本文所做的。
在进入特征提取部分之前,从”ULg多模式嗜睡数据库“(也称为DROZY)获取数据,其中包含各种类型的嗜睡相关数据(信号.图像等)。
该数据集包含大约45个视频片段,这些视频片段根据Karolinska睡意量表(KSS)进行标记。KSS评分范围从1到9,其中1表示非常警觉,9表示非常困倦。
由于此数据集中缺少数据和标签,标签从1-9转换为1-3,分别表示无嗜睡.中度嗜睡和高度嗜睡。我本可以使用视频分类过程,但由于数据不足,我首先提取特征并将其用作模型输入。这样,模型将使用更少的数据来获得更准确的结果。
特征提取
对于这个特定的任务,我将使用TensorFlow-GPU2.6和Python3.6,以及预先安装了pip的open-cv.dlib和scipy库。
特征提取所需的所有库:
从scipy.spacial导入dist距离
从imutils.video导入FileVideoStream
从imutils.video导入VideoStream
从imutils导入面_utils
将numpy导入为np
导入argparse
导入imutils
导入时间
导入dlib
导入cv2
导入日期时间
导入csv
导入操作系统
导入数学
平均眨眼持续时间:眼睛纵横比低于0.3,然后高于0.3的持续时间被检测为眨眼。闪烁发生的时间称为闪烁持续时间。平均每分钟闪烁持续时间以计算平均闪烁持续时间。
#抓取左侧面部标志的索引
#右眼
(lStart,lEnd)=脸_utils.FACIAL_LANDMARKS_IDXS〔”左_眼”〕
(rStart,rEnd)=脸_utils.FACIAL_LANDMARKS_IDXS[“右眼”]
def eye_纵横比(eye):
A=dist.euclian(眼睛〔1〕,眼睛〔5〕)
B=dist.euclian(眼睛[2],眼睛[4])
C=分布核素(眼睛[0],眼睛[3])
耳朵=(A+B)/(2.0*C)
回程耳
闪烁频率:每分钟闪烁的次数称为闪烁频率。
定义时间_差异(开始时间_结束时间_):
开始时间=开始时间.split()
对于范围(0,8)内的i:
小时=int(开始时间[3])
分钟=int(开始时间[4])
秒=int(开始时间[5])
毫秒=int(开始时间[6])
微秒=int(开始时间[7])
#将其转换为微秒
t1.m1.s1.ms1.mis1=小时.分钟.秒.毫秒.微秒
开始时间微秒=mis1+1000*(ms1+1000※(s1+60*(m1+60*t1))
结束时间=结束时间.split()
对于范围(0,8,1)中的x:
小时=int(结束时间[3])
分钟=int(结束时间[4])
秒=int(结束时间[5])
毫秒=int(结束时间[6])
微秒=int(结束时间[7])
t2,m2,s2,ms2,mis2=小时,分钟,秒,毫秒,微秒结束时间时间微秒=mis2+1000*
#寻找眨眼的持续时间
时间_差异=结束_时间_微秒-开始_时间
#打印”时间”差值(微秒)=”,时间”差值
返回时间_不同
口腔纵横比:计算MAR来检测一个人是否在打哈欠。
(omouth,emouth)=face_utils.FACIAL_LANDMARKS_IDXS〔”mouth”〕
def mouth_纵横比(mouth):
#计算两组
#垂直口界标(x,y)-坐标
A=分布核素(口〔2〕,口〔10〕)#51,59
B=分布核素(口[4],口[8])#53,57
#计算水平面之间的欧氏距离
#口界标(x,y)-坐标
C=分布核素(口[0],口[6])#49,55
#计算嘴长宽比
mar=(A+B)/(2.0*C)
#返回嘴部纵横比
回程线
头部姿势:计算每个帧的不同角度以获得头部姿势。
def getHeadTiltAndCoords(大小,图像_点,帧_高度):
焦距=尺寸〔1〕
中心=(尺寸〔1〕/2,尺寸〔0〕/2)
相机矩阵=np.阵列(〔焦距〕长度,0,中心〔0〕〕,〔
0,焦距,中心[1]],[0,0,1]],dtype=”double”)
dist_coeff=np.zeros((4,1))#假设没有镜头畸变
(_,旋转_矢量,平移_矢量)=cv2.solvePnP(模型_点,图像_点.相机_矩阵,分布_系数,标志=cv2.解决方案_迭代)#标志=CV 2.CV迭代)
(鼻端_点2D,_)=cv2.projectPoints(np.array(
〔(0.0,0.0,1000.0)〕),旋转_矢量,平移_矢量,相机_矩阵,距离_系数)
#从旋转向量获得旋转矩阵
旋转_矩阵,_=cv2.Rodrigues(旋转_矢量)
#以度计算头部倾斜角度
头部倾斜度=abs(
[-180]-np.rad2deg([rotationMatrixToEulerAngles(旋转矩阵)[0]])
#计算两条线的起点和终点以供说明
起始点=(int(图像_点[0][0]),int(图像_点[0][1]))
结束点=(int(鼻子结束点2D[0][0][0]),int(鼻子终止点2D[0][0][1]))
终点_点_alternate=(终点_点[0],框架_高度/2)
返回头_倾斜_度,起点_点,终点_点
这就是我的特征提取过程。
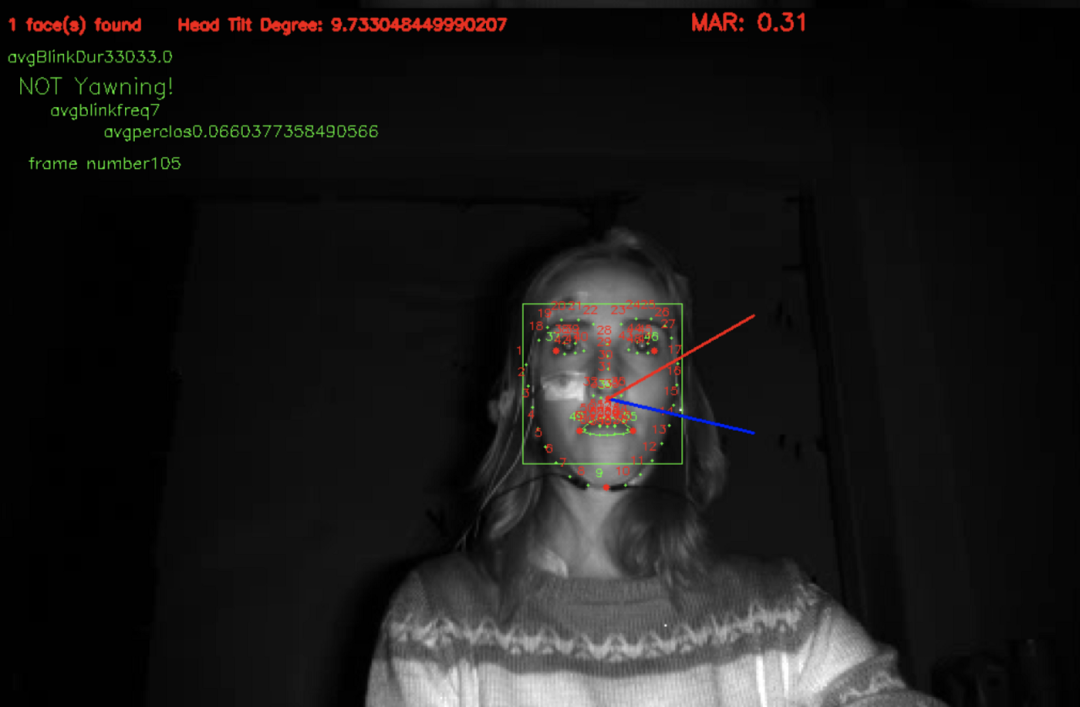
是时候做一个模型了!
因为我们已经完成了特征选择,所以我们不需要构建复杂的模型。我将使用人工神经网络
将numpy导入为np
导入sklearn
从sklearn导入预处理
#来自sklearn.datasets.samples_生成器导入生成_blobs
#来自sklearn.预处理导入LabelEncoder.StandardScaler
导入csv
导入操作系统
从张量流导入keras
随机导入
从keras.models导入Sequential
从keras.layers导入Dense.Dropout.Activation.BatchNormalization
来自keras导入正则化器
导入tplotlib.pyplot作为plt
#来自keras.utils导入绘图_模型
导入sklearn
从sklearn.metrics导入混沌矩阵
从sklearn.metrics导入准确度_得分
从sklearn.metrics导入分类报告
进口泡菜
从keras.utils导入np_utils
来自keras导入优化器
从keras.models导入load_模型
这是深度学习中最简单的模型设计,但由于特征提取,它是有效的。因为我们计算每分钟的困倦程度,所以确保连接输入并将其传递给模型。
#设计模型
模型=顺序()
model.add(Dense(64,输入_ dim=6,激活=’relu’))
model.add(删除(0.001))
model.add(Dense(64,输入_ dim=6,激活=’relu’))
model.add(删除(0.001))
model.add(Dense(32,输入_ dim=6,激活=’relu’))
model.add(Dense(16,输入_ dim=6,激活=’relu’))
model.add(Dense(4,激活=’softmax’,使用_bias=False))
#编译模型
#adam=keras.优化器adam(lr=0.01)
adam=keras.optimizers.adam(lr=0.001)
model.compile(损失=”类别_交叉熵”,优化器=adam,度量=[“准确姓”])
#符合模型
checkpoint=keras.callbacks.ModelCheckpoint(文件路径=”训练的模型/DrowDet模型(输出4).hdf5″,周期=1)
tbCallBack=keras.callbacks.TensorBoard(log_dir=’./scalar’
直方图_freq=0,写入_graph=True,写入_images=True)历史=模型拟合(Xtrain,Ytrain,epochs=50,批次_size=256,回调=〔checkpoint,tbCallBack〕,验证_data=(Xval,Yval))
使用精度和验证精度以及模型性能的培训损失和验证损失。
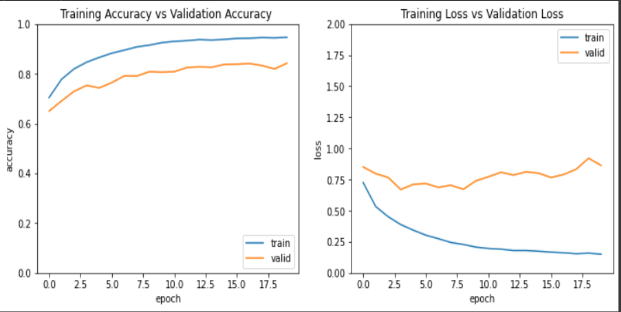
超级参数调整模型!我改变了学习率(0.01->0.001).不同的优化器(RMSprop)和周期数(20->50)。
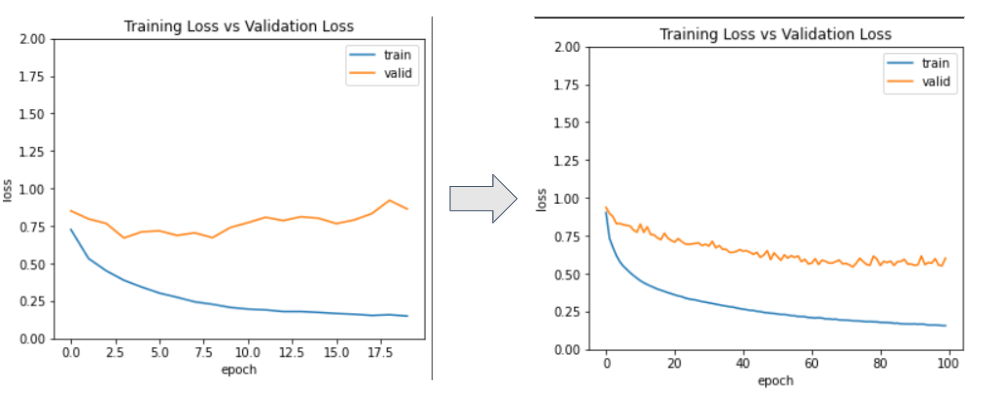
使用Sklearn的混淆矩阵,我在测试集上评估了模型,获得了73%的准确率和89%的训练准确率。使用大约4个隐藏层,我在测试集上获得了大约74%的准确率,在训练数据集上获得93%的准确度。
600学习网 » 驾驶员嗜睡分类 – 深度学习-600学习网



