
基于卷积神经网络的图像分类-600学习网
600学习网终身会员188,所有资源无秘无压缩-购买会员
现在是学习卷积神经网络及其在图像分类中的应用的时候了。

什么是卷积?
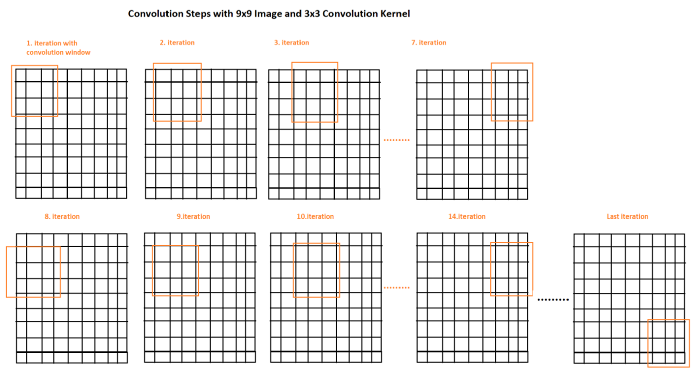
卷积运算是使用具有恒定大小的”窗口”移动图像并将图像像素乘以卷积窗口以获得输出图像的过程。让我们看看下面的示例:
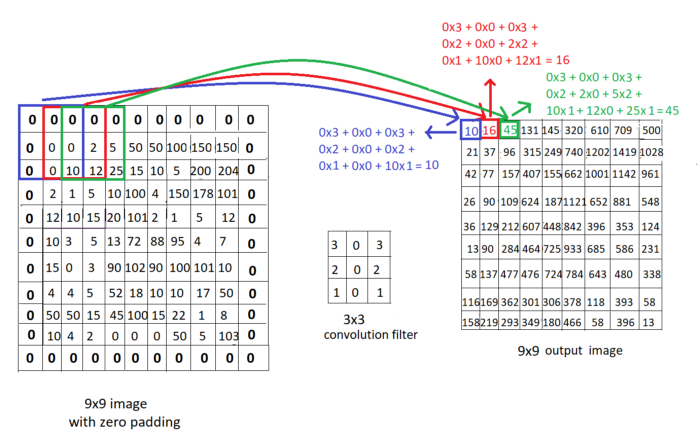
我们看到一个9×9图像和一个3×3卷积滤波器,其恒定权重为3032020101,以及卷积运算的计算。尝试使用下面显示的滤波器遍历图像,更好地理解如何通过卷积计算输出图像的这些像素。
窗口.滤波器.核心和掩码是指”卷积滤波器”的不同方式。我们也将在本文中使用这些术语。
填满
填充是向输入图像帧添加额外像素的过程,主要是为了保持输出图像的大小与输入图像的大小相同。最常见的填充技术是添加零(称为零填充)。
大步走
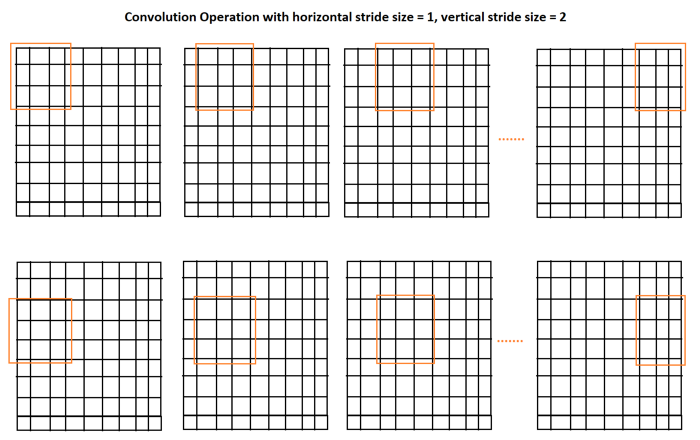
步长是我们使用卷积窗口遍历图像时每次迭代的步长。在下面的示例中,我们实际看到步长为1,因此我们将窗口移动1。现在,让我们看另一个示例,以更好地理解水平步长=1,垂直步长=2:
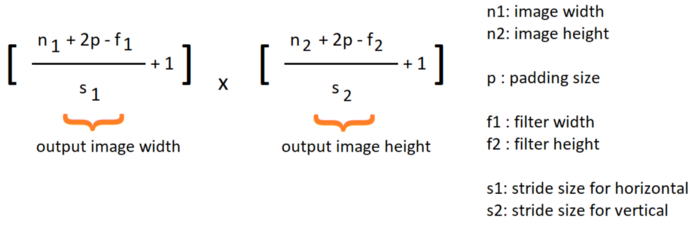
因此,填充大小.步长大小.过滤器大小和输入大小将影响输出图像的大小。根据这些不同的参数,输出图像的大小公式如下:
到目前为止,我们只研究了一种应用于输入图像的卷积运算。现在让我们看看什么是卷积神经网络以及我们如何训练它们。
卷积神经网络(CNN)
如果一个层用作卷积窗口,并且窗口中的每个像素实际上是一个权重(而不是我们在前一篇文章中学习的完全连接的神经网络),那么这就是一个卷积神经网络。
我们的目标是训练模型在最后以最小的成本更新这些权重。因此,与前面的例子相反,我们的卷积滤波器没有任何恒定值,我们应该让模型找到它们的最佳值。
因此,简单的CNN是一系列卷积运算,如下所示:
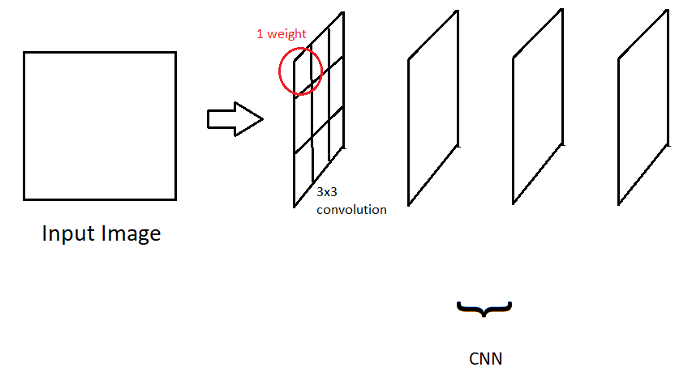
基于CNN的图像分类
但是如何使用CNN实现图像分类呢?
图像分类之间的唯一区别是我们现在处理的是图像,而不是结构化数据,如房价和房间号。
每个卷积操作都将参与提取图像特征,如耳朵.脚.狗嘴等。随着卷积层的加深,这一特征提取步骤将更加深入。在第一层,我们只得到图像的一些边缘。
因此,卷积层负责提取重要特征。最后,为了有一个完整的图像分类模型,我们只需要一些完全连接的输出节点来根据它们的权重确定正确的图像类别!
让我们假设狗有分类问题。在这种情况下,在训练结束时,一些输出节点将表示狗的特征和一些猫的特征。
如果通过这些卷积层的输入图像在激活函数结束时提供较高的值,则狗将被分类为狗。否则,它将被归类为猫。让我们将这个过程可视化:
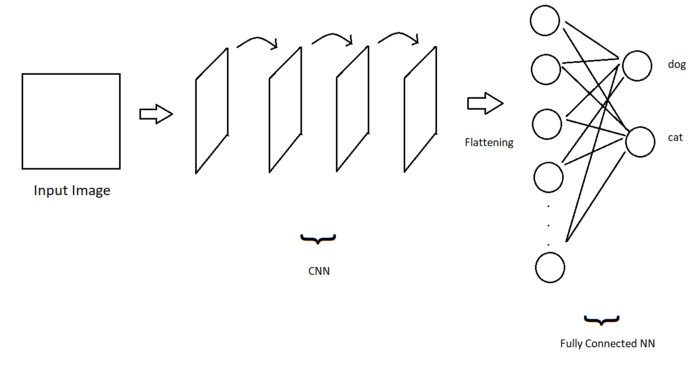
CNN+完全连接的神经网络创建了一个图像分类模型!
在讨论用于图像分类的常见CNN架构之前,让我们看一些更复杂.更现实的CNN示例:
当我们谈论CNN层时,我们不仅讨论一层中的卷积核;事实上,多个卷积核心可以创建一个卷积层。因此,我们将所有这些卷积滤波器一个接一个地应用于输入图像,然后将它们传递给下一个卷积
重要的是要逐步减少参数的数量,只从特征图中选择最重要的特征(每个卷积层的输出图。正如我们前面所说,更深的卷积层具有更具体的特征)。有两种常见的池类型:
最大池数
基本想法是再次使用窗户。此时,不使用重量。遍历特征图时,选择最大像素值作为输出。

我们使用相同的公式来计算具有卷积的最大池的输出映射大小,正如我前面提到的。重要的一点是,因为目的是减少参数大小,所以给出填充大小=0和字符串大小=池内核的大小是一种合理且常见的方法,正如我们在本例中所做的那样。
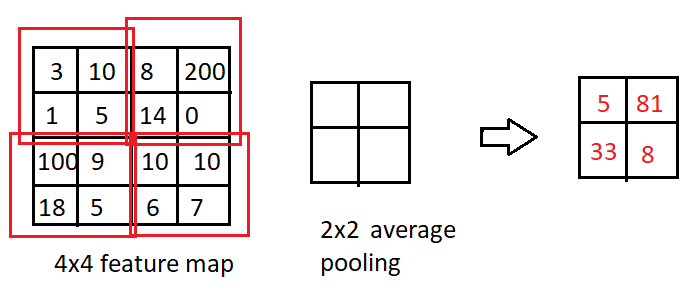
平均池数
我们不会根据最大像素计算输出,而是根据池核心中像素的平均值计算输出。
通用卷积神经网络结构
ImageNet大规模视觉识别挑战赛(ILSVRC)多年来一直是一项非常受欢迎的比赛。我们将研究不同年份的比赛获胜者。这些是图像分类任务中最常见的架构。与其他型号相比,它们具有更高的性能。
ImageNet是一个数据集,包含1281167张训练图像.50000张验证图像和100000张1000个类的测试图像。
验证数据集:除了用于任何模型的训练步骤的训练数据集和用于在训练步骤完成后测试模型以计算模型精度性能的测试图像之外,这是模型之前没有看到的数据,即它在训练阶段不参与反向传播权重更新阶段,而是用于测试,以便真正跟踪训练阶段的进度。
·AlexNet(2012年)
该模型由8层.5层卷积和3层全连接组成。
对于RGB输入图像(3个通道)
包括6000万个参数
ImageNet测试数据集的最终误差为15.3%
该模型首次使用ReLU激活功能。除了最后一个完全连接的层具有Softmax激活功能外,ReLu被用作整个模型的激活功能
使用0.5%Dropout。
使用动量为0.9.批次大小为128的随机梯度下降法
使用标准偏差为0.01的零均值高斯分布初始化权重
偏移量用恒定值1初始化。
学习率初始化为0.01,”权重衰减正则化”的应用为0.0005

在上图中,我们可以看到AlexNet架构。我们有1000个完全连接的节点,因为ImageNet数据集有1000个类。
在这个架构中,我们还遇到了一些我之前没有提到的术语:
动量梯度下降:这是梯度下降计算的优化。我们将梯度下降的导数添加到梯度下降计算中。我们将动量超参数乘以这个附加部分。对于这种结构,动量超参数为0.9。
高斯分布的权重初始化:在训练模型之前,有不同的方法来初始化我们的权重。例如,将每个权重设置为0是一种方式,但这是一种糟糕的方式!相比之下,根据高斯分布初始化所有权重是一种常见的方法。我们只需要选择分布的平均值和标准偏差,我们的权重将在这个分布范围内。
权重衰减优化:当本文使用SGD(随机梯度下降)时,L2正则化也是如此!
·VGG16(2014)
VGG架构是具有13个卷积和3个完全连接的16层模型。
它有1.38亿个参数
测试数据集中的7.5%错误
与AlexNet相反,每个卷积层中的所有核心使用相同的大小。这是一个3×3内核,步长=1,填充=1。最大池为2×2,步长=2
与AlexNet一样,ReLu用于隐藏层,Softmax用于输出层。动量为0.9的SGD,衰减参数为0.00005的权重衰减正则化,初始学习率为0.01,权重初始化为高斯分布。
作为一个小的不同
如果您想研究更多类型的卷积神经网络,我们建议您搜索Inception.SeNet(2017年ILSVRC获奖者)和MobileNet。
现在是时候将VGG16与Python和Tensorflow结合起来应用图像分类了!
VGG架构实现
#导入必要的层
从tensorflow.keras.layers导入输入.Conv2D.Dropout.MaxPool2D.Flatten.Dense
从tensorflow.keras导入模型
从tensorflow.keras.preprocessing.image导入ImageDataGenerator
从tensorflow.keras.regularizers导入l2
将tensorflow导入为tffrom tensorfflow.keras.callbacks导入EarlyStopping,ModelCheckpoint
导入操作系统
将matplotlib.pyplot导入为plt
导入系统
从tensorflow.keras.callbacks导入CSVLogger
模型_ FNAME=”训练的_模型.h5″
base_ dir=”数据集”
tmp_型号_名称=”tmp.h5″
输入_大小=224
批次_尺寸=16
物理设备=tf.config.list物理设备()
打印(“设备:”,物理设备)
打印(“使用:”)
print(‘u2022 Python版本:’,sys.version)
打印(‘u2022 TensorFlow版本:’,tf.__版本__)
打印(“u2022 tf.keras版本:”,tf.keras.__版本__)
print(如果tf.test.为_GPU_available(),则为”u2022在GPU上运行”,否则为”未找到u2022 GPU设备。在CPU上运行”)
计数=0
前_ acc=0
如果不存在os.path(型号_ FNAME):
“””创建VGG模型”””
#输入
input=输入(形状=(input_SIZE,input_SIZE,3))
权重_初始值设定项=tf.keras.initializers.RandomNormal(平均值=0.0,标准偏差=0.01,种子=无)
bias _ initializer=tf.keras.initializers.Zeros()
#第一转换块
x=Conv2D(滤波器=64,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始化器=bias _初始化器)(输入)
x=Conv2D(滤波器=64,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=MaxPool2D(池大小=2,步幅=2,填充=”相同”)(x)
#2转换块
x=Conv2D(滤波器=128,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=128,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=MaxPool2D(池大小=2,步幅=2,填充=”相同”)(x)
#3转换块
x=Conv2D(滤波器=256,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=256,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=256,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=MaxPool2D(池大小=2,步幅=2,填充=”相同”)(x)
#4转换块
x=Conv2D(滤波器=512,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=512,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=512,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=MaxPool2D(池大小=2,步幅=2,填充=”相同”)(x)#第五转换块
x=Conv2D(滤波器=512,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=512,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=Conv2D(滤波器=512,核_大小=3,填充=”相同”,激活=”relu”,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始值设定器=偏置_初始化器)(x)
x=MaxPool2D(池大小=2,步幅=2,填充=”相同”)(x)
#全连接层
x=扁平(x)
x=压降(0.5)(x)
x=Dense(单位=4096,激活=’relu’,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始化器=bias _初始化器)(x)x=Dropout(0.5)(x
x=Dense(单位=4096,激活=’relu’,核_初始化器=权重_初始化器,核_正则化器=l2(0.00005),偏置_初始化器=bias _初始化器)(x)
输出=密集(单位=2,激活=’softmax’)(x)
#创建模型
模型=模型(输入=输入,输出=输出)
m=型号
m. 保存(tmp_模型_名称)
德尔姆
tf.keras.backend.clear _ session()
模型.summary()
“””准备培训数据集”””
train _ dir=os.path.join(base _ dir,’train’)
val_dir=os.path.join(base_dir,”validation”)
train_batches=ImageDataGenerator(重新缩放=1/255.)。flow_from_directory(train_dir,target_size=(INPUT_size,INPUT _ size),shuffle=True,seed=42,batch_size=batch_SIZ)
val_batches=ImageDataGenerator(重新缩放=1/255.).flow_from_directory(val_dir,target_size=(INPUT_size,INPUT _ size),shuffle=True,seed=42,batch_size=batch_SIZ)
“””列车”””
类CustomLearningRateScheduler(tf.keras.callbacks.Callback):
def_init_(自我,时间表):
super(CustomLearningRateScheduler,自我).__init___()
self.schedule=时间表
在__epoch_end(self,epoch,logs=None)上定义:
如果没有hasattr(self.model.optimizer,”lr”):
raise ValueError(“优化器必须具有”lr”属姓。”)
#从模型的优化器中获取当前的学习率。
lr=float(tf.keras.backend.get_value(self.model.optimizer.learning _rate))
#调用schedule函数,获取计划学习率。
#keys=list(logs.keys())
#打印(“键”,键)
val_ acc=logs.get(“val_二进制_精度”)
计划的_ lr=自身计划(lr,val _ acc)
#在这个时期开始之前将值设置回优化器
tf.keras.backend.set_value(self.model.optimizer.lr,scheduled_lr)
def learning_rate_scheduler(lr,val_acc):
全局计数
全球上一个账户
如果val _ acc==前一个_ acc:
#打印(“acc”.val_acc.”previous acc”和previous-acc)
计数+=1
否则:
计数=0
如果计数>=5:
print(“acc与10历元相同,学习率降低/10”)
计数=0
lr/=10
打印(“新学习率:”,lr)
上一个账户=有效账户
返回lr
#通过确定损失函数二进制交叉熵来编译模型,优化器为SGD
model.compile(优化器=tf.keras.optimizers.SGD(lr=0.0000001,动量=0.9)
loss=tf.keras.loss.BinaryCrossentropy()
metrics=[tf.keras.metrics.BinaryAccuracy()]
样本_权重_模式=〔无〕)
早停=早停(监视器=”val _ loss”,耐心=10)
checkpointer=ModelCheckpoint(filepath=MODEL_FNAME,verbose=1,save_best_only=True)
csv_logger=CSVLogger(‘log.csv’,append=True,separator=”)
历史=模型拟合(列_批
验证_数据=val_批次
epochs=100
verbose=1
shuffle=真
回调=〔checkpointer,提前停止,CustomLearningRateScheduler(学习速率调度程序),csv_logger〕)
“””绘制列车和验证损失”””
plt.plot(history.history[“损失”])
plt.plot(history.history[‘val_loss’])
plt.title(“模型损失”)
伊拉贝尔(“损失”)
plt.xlabel(“纪元”)
plt.图例([“列车”,”验证”],loc=”左上角”)
plt.show()
“””绘制列车和验证精度”””
plt.plot(history.history〔’二进制精度’〕)
plt.plot(history.history〔’val〕二进制精度〕)
plt.title(“模型精度”)
plt.ylabel(“精度”)
plt.xlabel(“纪元”)
plt.图例([“列车”,”验证”],loc=”左上角”)
plt.show()
打印(“培训结束”)
否则:
“””测试”””
test_dir=os.path.join(base_dir,’test’)
test_batches=ImageDataGenerator(重新缩放=1/255.).flow_from_directory(test_dir,target_size=(INPUT_size,INPUT _ size),class_mode=”categorical”,shuffle=False,seed=42,batch_size=1)
模型=tf.keras.models.load_模型(模型_FNAME)
模型.summary()
#测试数据评估
得分=模型评估(测试_批)
打印(“metric name”,model.metrics_name)
打印(model.metrics_名称[0],分数[0])
打印(model.metrics_名称[1],分数[1])
tf.keras.backend.clear _ session()
这是使用Python和Tensorflow实现的VGG16。让我们看看代码
·首先,我们检查TensorFlow Cuda Cudnn安装是否正常,以及TensorFlow是否可以找到我们的GPU。因为如果不是这样,则意味着存在包冲突或错误。我们应该解决这个问题,因为使用CPU进行模型训练太慢了。
·然后,我们使用Conv2D函数为卷积层创建VGG16模型。MaxPool2D函数是最大池层,平坦化函数输出可传输到CNN的全连接层的平坦化输入,Dense函数是全连接层,Dropout函数在最后一个全连接层之间添加了Dropout优化。如您所见,在使用相关层函数时,我们应该向层添加权重初始化.偏差初始化和l2正则化器1×1。请注意,正态分布是高斯分布的同义词,因此当您看到weight_initializer=tf.keras.initializers时。RandomNormal(平均值=0.0,标准偏差=0.01,种子=无),不要混淆
·两个类将用于测试这个模型,而不是1000个类来测试巨大的ImageNet数据集,因此我将输出层从1000个节点更改为2个节点
·使用ImageGenerator函数和flow_from_directory,我们将数据集准备为可以使用TensorFlow模型的向量。我们也在这里给出了批量大小。(因为我的计算机内存不足,我可以给出16个,而不是论文中提到的256个
·模型。compile()函数是训练模型之前的最后一部分。我们决定使用哪个优化器(具有动量的SGD).哪个损失函数(因为我们的示例中有两个类)以及训练期间的计算性能指标(二进制精度)。
·使用模型。适合训练我们的模型。添加了一些选项,例如”EarlyStopping”和”ModelCheckPoint”回调。如果验证损失在10个历元内没有增加,则第一个历元停止训练。如果验证丢失比前一个历元好,那么模型检查点不仅在最后保存我们的模型,而且在训练期间保存模型。
·CustomLearningRateScheduler是我手动实现的学习速率调度器。它用于应用”如果验证精度停止提高,我们将通过除以10来更新学习率”
·在培训结束时,我将验证和培训数据集的准确姓,并可视化损失图。
·最后一部分是使用测试数据集测试模型。我们检查是否有任何名为”trained_model.h5″的训练模型。如果没有,我们训练一个模型。如果有,我们使用此模型来测试性能
我想解释解释代码时使用的一些术语:
·验证集精度:验证集精度是衡量验证数据集中模型性能的指标。它只是检查验证数据集中有多少图像预测是正确的。我们还将对训练数据集执行相同的检查。但这只是为了我们监控模型,只有训练损失用于梯度下降计算
·迭代纪元:1次迭代是为批处理中的所有图像提供模型的过程。大纪元是指为训练数据集中的所有图像提供模型的过程。例如,如果我们有100幅图像,批处理=10,那么一个历元将有10次迭代。
·扁平化:这仅仅是为了将CNN输出整形为具有1D输入,这是从卷积层向全连接层传输的唯一方法。
·现在让我们检查结果
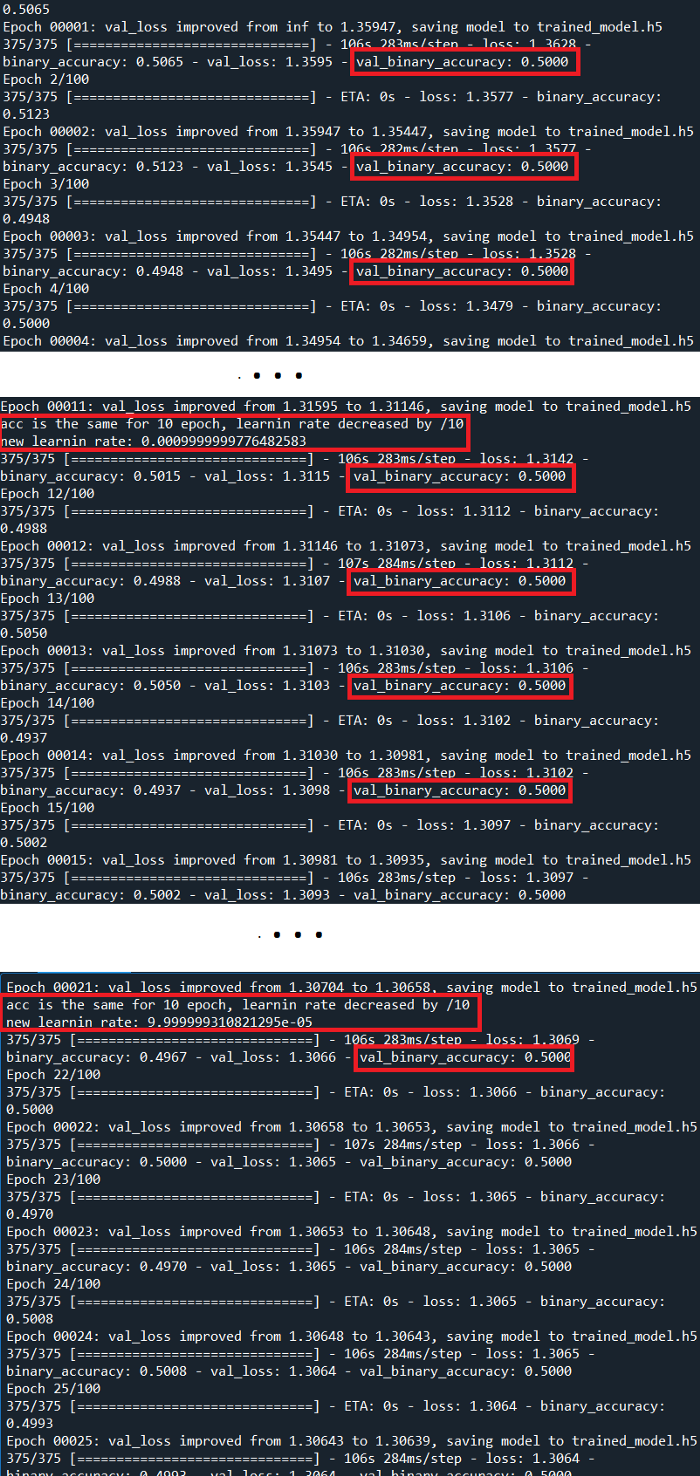
即使通过监控验证精度来改变学习率,结果也不是很好,验证精度也没有提高。但为什么它不能像VGG16论文那样直接工作呢?
1.在最初的论文中,我们讨论了374个时代的1000个输出类和1500000幅图像。不幸的是,使用这个数据集并训练1000个类的模型需要几天时间。如前所述,我使用了两个类的数据集,并将输出层更改为具有两个输出节点。
1.模型架构和数据集需要不同的优化,因此运行良好的模型可能不适用于其他数据集。
3.微调超级参数以改进模型与了解如何首先构建模型一样重要。您可能已经注意到我们需要微调多少超级参数
·权重和偏移初始化
·损失函数选择
·初始学习率选择
·优化器选择(梯度下降法)
·辍学的使用
·数据扩展(如果您没有足够的图像,或者它们太相似,则希望获得同一图像的不同版本)
等待
但是,在你对如何优化这么多变量感到悲观之前,你想提出两点。
1.转移学习
这是一个非常重要的方法。我们使用预先训练的模型,用我们自己的数据集训练它们。在我们的示例中,我们将不仅使用VGG16架构,而且使用使用VGG16架构和ImageNet数据集训练的模型。我们将使用比ImageNet小得多的数据集对其进行再培训。
这种方法为我们提供了一个并非未知的起点-一些随机权重。我们的数据集可能包含不同的对象,但不同的对象有一些基本的共同特征,例如边和圆。为什么不使用它们而不是从头开始?我们将看到这种方法如何减少时间消耗并提高精度性能。
2.当查看我们的输出时,我们发现问题不是模型停止学习,而是它没有开始学习!精度从0.5开始,并且没有改变!这个具体的结果给了我们一个非常明确的信息:我们应该降低学习率,让模型开始学习。请记住,学习速率是学习步长,以及每次迭代的梯度下降计算对权重的影响程度。如果速率太大,步长太大,我们无法控制权重更新,因此模型无法学习任何东西。
以下代码仅包括转移学习的变化,其中使用了具有预训练权重的Tensorflow内置模型和学习率低(0.001)的模型
#-*-编码:utf-8-*
"""
创建于2021 12月29日星期三20:56:04
作者:aktas
"""
#导入必要的层
从tensorflow.keras.preprocessing.image导入ImageDataGenerator
从tensorflow.keras.regularizers导入l2
将张量流导入为tf
从tensorflow.keras.callbacks导入EarlyStopping,ModelCheckpoint
导入操作系统
将matplotlib.pyplot导入为plt
导入系统
从tensorflow.keras.callbacks导入CSVLogger
从tensorflow.keras.applications导入vgg16,imagenet _ utils
从tensorflow.keras.layers导入Dense,Flatten
从tensorflow.keras.models导入模型
模型_ FNAME=”预处理模型_模型.h5″
tmp_型号_名称=”tmp.h5″
base_ dir=”数据集”
输入_大小=224
批次_尺寸=16
物理设备=tf.config.list物理设备()
打印(“设备:”,物理设备)
打印(“使用:”)
print(‘u2022 Python版本:’,sys.version)
打印(‘u2022 TensorFlow版本:’,tf.__版本__)
打印(“u2022 tf.keras版本:”,tf.keras.__版本__)
print(“u2022在GPU上运行”,如果tf.test.为_GPU_available()else”
未找到u2022 GPU设备。在CPU上运行)
计数=0
前_ acc=0
如果不存在os.path(型号_ FNAME):
base_model=vgg16.vgg16(权重=”imagenet”,包括_top=False,input_shape=(input_SIZE,input _ SIZE))
m=底座_型号
米。
tf.keras.backend.clear _ session()
print(“基本模型中的层数:”,len(base_model.layers))
base_模型.trainable=假
last_output=base_model.output
x=Flatten()(最后_个输出)
x=稠密(2,活化=’softmax’)(x)
模型=模型(输入=[base_model.input],输出=[x])
模型.summary()
“””准备培训数据集”””
train_dir=os.path.join(base_dir,’train’)val_dir=os.path.join(base_dir.’validation’)
train_batches=ImageDataGenerator(重新缩放=1/255.)。flow_from_directory(train_dir,target_size=(INPUT_size,INPUT _ size),shuffle=True,seed=42,batch_size=batch_SIZ)
val_batches=ImageDataGenerator(重新缩放=1/255.).flow_from_directory(val_dir,target_size=(INPUT_size,INPUT _ size),shuffle=True,seed=42,batch_size=batch_SIZ)
“””列车”””
类CustomLearningRateScheduler(tf.keras.callbacks.Callback):
def_init_(自我,时间表):
super(CustomLearningRateScheduler,自我).__init___()
self.schedule=时间表
在__epoch_end(self,epoch,logs=None)上定义:
如果没有hasattr(self.model.optimizer,”lr”):
raise ValueError(“优化器必须具有”lr”属姓。”)
#从模型的优化器中获取当前的学习率。
lr=float(tf.keras.backend.get_value(self.model.optimizer.learning _rate))
#调用schedule函数,获取计划学习率。
#keys=list(logs.keys())
#打印(“键”,键)
val_ acc=logs.get(“val_二进制_精度”)
计划的_ lr=自身计划(lr,val _ acc)
#在这个时期开始之前将值设置回优化器
tf.keras.backend.set_value(self.model.optimizer.lr,scheduled_lr)
def learning_rate_scheduler(lr,val_acc):
全局计数
全球上一个账户
如果val _ acc<=上一个_ acc:
#打印(“acc”.val_acc.”previous acc”和previous-acc)
计数+=1
否则:
上一个账户=有效账户
计数=0
如果计数>=5:
print(“acc与10历元相同,学习率降低/10”)
计数=0
lr/=10
打印(“新学习率:”,lr)
返回lr
#通过确定损失函数二进制交叉熵来编译模型,优化器为SGD
model.compile(优化器=tf.keras.optimizers.SGD(lr=0.001,动量=0.9),损失=tf.keras.loss.BinaryCrossentropy(),度量=〔tf.kera.metrics.BinaryAccuracy()〕,样本_权重_模式=〔无〕)
早停=早停(监视器=”val _ loss”,耐心=10)
checkpointer=ModelCheckpoint(filepath=MODEL_FNAME,verbose=1,save_best_only=True)
csv_logger=CSVLogger(‘log.csv’,append=True,separator=”)
历史=模型拟合(列_批
验证_数据=val_批次
epochs=100
verbose=1
shuffle=真
回调=〔checkpointer,提前停止,CustomLearningRateScheduler(学习速率调度程序),csv_logger〕)
“””绘制列车和验证损失”””
plt.plot(history.history[“损失”])
plt.plot(history.history[‘val_loss’])
plt.title(“模型损失”)
伊拉贝尔(“损失”)
plt.xlabel(“纪元”)
plt.图例([“列车”,”验证”],loc=”左上角”)
plt.show()
“””绘制列车和验证精度”””
plt.plot(history.history〔’二进制精度’〕)
plt.plot(history.history〔’val〕二进制精度〕)
plt.title(“模型精度”)
plt.ylabel(“精度”)
plt.xlabel(“纪元”)
plt.图例([“列车”,”验证”],loc=”左上角”)
plt.show()
打印(“培训结束”)
否则:
“””测试”””
test_dir=os.path.join(base_dir,’test’)
test_batches=ImageDataGenerator(重新缩放=1/255.).flow_from_directory(test_dir,target_size=(INPUT_size,INPUT _ size),class_mode=”categorical”,shuffle=False,seed=42,batch_size=1)
模型=tf.keras.models.load_模型(模型_FNAME)
模型.summary()
#测试数据评估
得分=模型评估(测试_批)
打印(“metric name”,model.metrics_name)
打印(model.metrics_名称[0],分数[0])
打印(model.metrics_名称[1],分数[1])
tf.keras.backend.clear _ session()
让我们检查结果:
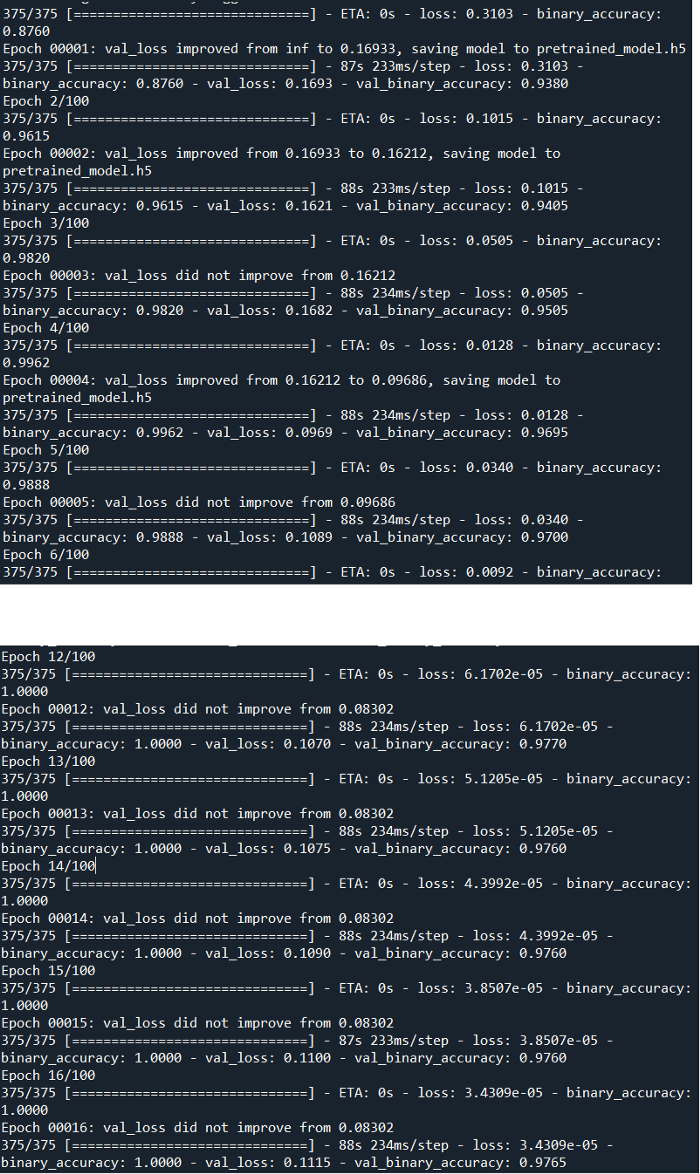
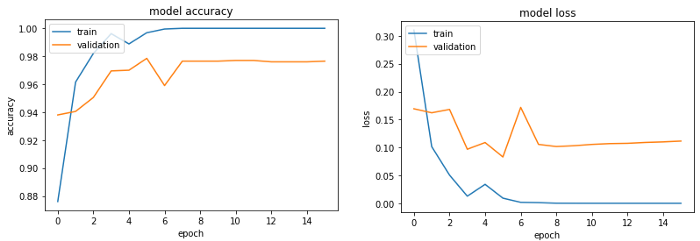
性能大大提高了,对吗?!我们可以看到,验证精度不再停留在0.97,而训练精度达到1.00。

一切似乎都很好!
我想与大家分享我的一些实验及其结果:
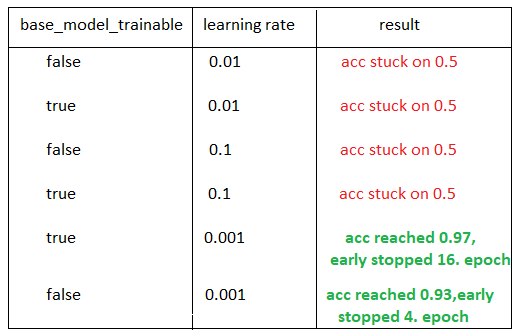
现在,我们可以进行以下分析:
如果我们有一个不兼容的学习率,转移学习本身仍然是不够的。
如果我们将base_model_trainable变量设置为False,这意味着我们不训练我们使用的模型,只训练我们添加的最后一个完整连接层。(VGG有1000个输出,因此我使用include_top=False代替最后一个完整连接层,并且我在预训练模型的末尾添加了自己的完整连接层
vgg_from_script实现的学习率从零改变,但验证的准确率仍为0.5,因此仅优化学习率本身是不够的。(至少如果你在微调后没有时间从头开始训练模型。)
您可以通过此链接访问使用的数据集。不要忘记将其与以下代码放在同一文件夹中(当然,培训完成后,.h和日志文件将出现!???):
https:/drive.google.com/drive/folders/1vt8HiybDroEMCvpdGQJx2T50Co4nZNYeusp=共享
使用Anaconda和Python=3.7,Tensorflow=2.2.0,Cuda=10.1,Cudnn=7.6.5使用GPU训练和测试我的模型。如果您不熟悉这些术语,下面是一个快速教程:
下载Anaconda(请为您的计算机选择正确的系统)
打开Anaconda终端,使用conda create-n im_class python=3.7 Anacond命令创建环境。环境可能是Anaconda最重要的属姓,它允许您独立地为不同的项目工作。您可以将任何包添加到您的环境中。如果您需要另一个包的另一个版本,您可以简单地创建另一个环境以防止另一个项目崩溃,等等。
使用conda activate im_class命令进入您的环境以添加更多的包(如果您忘记了这一步,您基本上不会更改环境,但会在所有的anaconda空间中进行更改)
使用pip install Tensorflow GPU==2.2.0安装具有GPU功能的Tensorflow
使用命令conda Install cudatoolkit=10.1安装CUDA和Cudnn
现在您可以测试上面的代码了!
请注意,包版本之间的冲突是一个巨大的问题。这将帮助您减少构建环境的时间。
您已经完成了卷积神经网络图像分类教程。您可以尝试从头开始构建任何模型(甚至是您自己的模型),对其进行微调,将迁移学习应用于不同的体系结构,等等。
参考文献

600学习网 » 基于卷积神经网络的图像分类-600学习网



