
使用 Google Colab 训练的图像分类模型-600学习网
600学习网终身会员188,所有资源无秘无压缩-购买会员
介绍
图像分类是根据预定原理对图像中的像素组进行分类和识别的过程。在创建分类规则时,使用一个或多个光谱或文本质量是可行的。两种流行的分类技术是”有监督”和”无监督”。

图像分类是如何工作的?
使用标记的样本照片,训练模型检测目标类别(图像中要识别的对象)。监督学习的一个例子是图像分类。原始像素数据是早期计算机视觉算法的唯一输入。
然而,单个像素数据不能提供足够一致的表示,以包括图像中表示的项目的许多振荡。对象的位置.背景.环境照明.相机角度和相机焦点都会影响原始像素数据。
传统的计算机视觉模型添加了从像素数据衍生的新组件,如纹理.颜涩直方图和形状,以更灵活地建模对象。这种方法的缺点是特征工程变得非常耗时,因为需要更改大量输入。
哪些音调对猫的分类很重要?形状的定义应该有多灵活?因为特征必须精确调整,所以很难创建健壮的模型。
训练图像分类模型
本教程使用基本的机器学习工作流:
·分析数据集
·创建输入管道
·构建模型
·培训模式
·分析模型
设置和导入TensorFlow和其他库
导入itertools
导入操作系统
将matplotlib.pylab导入为plt
将numpy导入为np
将张量流导入为tf
导入tensorflow _ hub作为hub
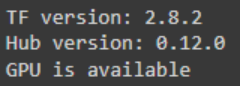
打印(“TF版本:”,TF.__版本__)
打印(“集线器版本:”,集线器.__版本__)
打印(“GPU为”,如果tf.config.list为物理设备(“GPU’),则为”可用”,否则为”不可用”)
输出如下:
选择要使用的TF2保存的模型模块
请注意,TF1 Hub格式模型在此不起作用。
有许多模型可以工作。只需从下面单元格中的列表中选择其他选项,然后继续使用笔记本。
在这里,我选择了Inception_v3,并从下面的列表中自动选择了299 x 299的图像大小。
模型名称=”resnet_v1_50″#@param〔’efficientnetv2-s’,’effiientnetv2&m’,’afficientetv2-l’,’ifficientnet v2-s-21k’,’高效网v2-m-21k’,’高效网络v2-l-21k′,’高效网上v2-xl-21k’,’有效网v2-b0-21k’,’高效上网v2-b1’-21k’.’效率网v2-b2-21k'”efficientnetv2-b3-21k-ft1k’,”efficient netv2-s-21k-ft1k’,”effecientnetV2-m-21k&ft1k”,”effficientnetv2&l-21k’ft1k’,”efefficiientnetV2-xl-21k-ft1k’,””effiientnetV2-b0-21kft1k’,k’,’efficientnetv2-b3-21k-ft1k'”efficientnetv2-b1’,”efficient netv2-b2’,”effecientnetV2-b3’,”高效网b0’,”有效网b1’,”效率网b2’,”高效网络b3’,”有效网络b4’,”效率网络b5’,”高效率网络b6’,”效能网b7’,”位s-r50x1’,”初始_ v3″.”初始_ resnet _ v2″‘resnet_v1_50’,’resnet_v2_101’,’resnet_v 1_152’,’resnet_v2_50’,’resnet_v2_101’,’resnet_v 2_152’,’nasnet_large’,’nadnet_mobile’,’pnasnet_lag’,’mobilenet_v3_100_224’,’mobilene_’移动电话网’v2’140’224’,’移动电话网络’v3’小’100’224”移动电话网_v3_小_075_224’,’移动电话网络_v4_大_100_224’,’移动手机网络_v3_大075 224’]
型号_手柄_地图={
“efficientnetv2-s”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_s/feature_vector/2”
“efficientnetv2-m”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_m/feature_vector/2”
“efficientnetv2-l”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_l/feature_vector/2”
“efficientnetv2-s-21k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_s/feature_vector/2”
“efficientnetv2-m-21k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_m/feature_vector/2”
“efficientnetv2-l-21k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_l/feature_vector/2”
“efficientnetv2-xl-21k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_xl/feature_vector/2”
“efficientnetv2-b0-21k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_b0/feature_vector/2”
“efficientnetv2-b1-21k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_b1/feature_vector/2”
“efficientnetv2-b2-21k”:”https://tfhub.dev/google/imagenet/efficient net_v2/imagenet21k_b2/feature_vector/2”
“efficientnetv2-b3-21k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_b3/feature_vector/2”
“efficientnetv2-s-21k-ft1k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_s/feature_vector/2”
“efficientnetv2-m-21k-ft1k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_m/feature_vector/2”
“efficientnetv2-l-21k-ft1k”:”https://tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_l/feature_vector/2”
“efficientnetv2-xl-21k-ft1k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_xl/feature_vector/2”
“efficientnetv2-b0-21k-ft1k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_b0/feature_vector/2”
“efficientnetv2-b1-21k-ft1k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_b1/feature_vector/2”
“efficientnetv2-b2-21k-ft1k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_b2/feature_vector/2”
“efficientnetv2-b3-21k-ft1k”:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet21k_ft1k_b3/feature_vector/2”
“efficientnetv2-b0″:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_b0/feature_vector/2”
“efficientnetv2-b1″:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_b1/feature_vector/2”
“efficientnetv2-b2″:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_b2/feature_vector/2”
“efficientnetv2-b3″:”https:/tfhub.dev/google/imagenet/efficient net_v2_imagenet1k_b3/feature_vector/2”
“efficientnet _b0″:”https:/tfhub.dev/tensorflow/efficient net/b0/feature-vector/1”
“efficientnet _b1″:”https:/tfhub.dev/tensorflow/efficient net/b1/feature-vector/1”
“efficientnet_b2″:”https:/tfhub.dev/tensorflow/efficient net/b2/feature-vector/1”
“efficientnet_b3″:”https:/tfhub.dev/tensorflow/efficient net/b3/feature-vector/1”
“efficientnet _b4″:”https:/tfhub.dev/tensorflow/efficient net/b4/feature-vector/1”
“efficientnet _b5″:”https:/tfhub.dev/tensorflow/efficient net/b5/feature-vector/1”
“efficientnet _b6″:”https:/tfhub.dev/tensorflow/efficient net/b6/feature-vector/1”
“efficientnet _b7″:”https:/tfhub.dev/tensorflow/efficient net/b7/feature-vector/1”
“bit_s-r50x1″:”https://tfhub.dev/google/bit/s-r50 x1/1”
“inception _v3″:”https://tfhub.dev/google/imagenet/inception_v3/feature-vector/4”
“inception _resnet _v2″:”https:/tfhub.dev/google/imagenet/inception_resnet _ v2/feature-vector/4”
“resnet_v1_50″:”https:/tfhub.dev/google/imagenet/resnet_v1_50/feature-vector/4”
“resnet_v1_101″:”https://tfhub.dev/google/imagenet/resnet_v1_101/feature-vector/4”
“resnet_v1_152″:”https:/tfhub.dev/google/imagenet/resnet_v1_152/feature-vector/4”
“resnet_v2_50″:”https:/tfhub.dev/google/imagenet/resnet_v2_50/feature-vector/4”
“resnet_v2_101″:”https://tfhub.dev/google/imagenet/resnet_v2_101/feature-vector/4”
“resnet_v2_152″:”https:/tfhub.dev/google/imagenet/resnet_v2_152/feature-vector/4”
“nasnet _ large”:”https://tfhub.dev/google/imagenet/nasnet _large/feature _ vector/4”
“nasnet _ mobile”:”https://tfhub.dev/google/imagenet/nasnet _mobile/feature _ vector/4”
“pnasnet _ large”:”https://tfhub.dev/google/imagenet/pnasnet _large/feature _ vector/4”
“mobilenet_v2_100_224″:”https://tfhub.dev/google/imagenet/mobilenet_v3_100 224/feature_vector/4”
“mobilenet_v2_130_224″:”https:/tfhub.dev/google/imagenet/mobilenet_v3_130 224/feature_vector/4”
“mobilenet_v2_140_224″:”https:/tfhub.dev/google/imagenet/mobilenet_v3_140 224/feature_vector/4”
“mobilenet_v3_small_100_224″:”https:/tfhub.dev/google/imagenet/mobilenet_v3_small_100 224/feature_vector/5”
“mobilenet_v3_small_075_224″:”https:/tfhub.dev/google/imagenet/mobilenet_v3_small_075_225/feature_vector/5”
“mobilenet_v3_large_100_224″:”https:/tfhub.dev/google/imagenet/mobilenet_v3_lage_100 224/feature_vector/5”
“mobilenet_v3_large_075_224″:”https:/tfhub.dev/google/imagenet/mobilenet_v3_lag_075_225/feature_vector/5”
}
模型_图像_尺寸_地图={
“efficientnetv2-s”:384
“efficientnetv2-m”:480
“efficientnetv2-l”:480
“efficientnetv2-b0″:224
“efficientnetv2-b1″:240
“efficientnetv2-b2″:260
“efficientnetv2-b3″:300
“efficientnetv2-s-21k”:384
“效率netv2-m-21k”:480
“效率netv2-l-21k”:480
“efficientnetv2-xl-21k”:512
“efficientnetv2-b0-21k”:224
“效率netv2-b1-21k”:240
“效率netv2-b2-21k”:260
“效率netv2-b3-21k”:300
“efficientnetv2-s-21k-ft1k”:384
“效率netv2-m-21k-ft1k”:480
“效率netv2-l-21k-ft1k”:480
“efficientnetv2-xl-21k-ft1k”:512
“efficientnetv2-b0-21k-ft1k”:224
“效率netv2-b1-21k-ft1k”:240
“效率netv2-b2-21k-ft1k”:260
“效率netv2-b3-21k-ft1k”:300
“efficientnet_b0″:224
“efficientnet_b1″:240
“efficientnet_b2″:260
“efficientnet_b3″:300
“efficientnet_b4″:380
“efficientnet_b5″:456
“efficientnet_b6″:528
“efficientnet_b7″:600
“初始_ v3″:299
“初始_ resnet _ v2″:299
“nasnet _ large”:331
“pnasnet _ large”:331
}
model_handle=model_handle_map.get(model_name)
像素=模型_图像_大小_地图.get(模型_名称,224)
print(f”所选型号:{model_name}:{model_handle}”)
图像_尺寸=(像素,像素)
打印(f”输入尺寸{图像大小}”)
批次_尺寸=16#参数{类型:”整数”}
所选模块的输入比例正确。较大的数据集对训练很有用,尤其是在微调(即每次读取图像时图像的随机失真)时。
我们的数据集应该如下图所示进行组织。

我们的自定义数据集现在必须上传到云磁盘。一旦需要扩展数据集,我们必须将数据扩展参数设置为true。
data_dir=”/content/Images”
def构建_数据集(子集):
return tf.keras.precessing.image_dataset_from_directory(data_dir,validation_split=.10,subset=subset,label_mode=”categorical”,seed=123,image_size=image_size,batch_size=1)
训练_ ds=构建_数据集(“训练”)
类名称=元组(train_ds.类名称)
列车_大小=列车_ ds.基数().numpy()
列车_ ds=列车_ ds.unbatch().批次(批次_尺寸)
列车_ds=列车_ds.repeat()
归一化_层=tf.keras.layers.Rescaling(1./255)
预处理_模型=tf.keras.Sequential(〔标准化_层〕)
do_data_扩增=False#@param{type:”boolean”}
如果做数据扩充:
预处理_ model.add(tf.keras.layers.RandomRotation(40))
预处理_ model.add(tf.keras.layers.RandomTranslation(0,0.2))
预处理_ model.add(tf.keras.layers.RandomTranslation(0.2,0))
#像旧的tf.keras.precessing.image.ImageDataGenerator()一样
#图像大小在读取时固定,然后应用随机缩放。
#随机裁剪,批量大小为1,稍后重新匹配。
预处理_ model.add(tf.keras.layers.RandomZoom(0.2,0.2))
预处理_model.add(tf.keras.layers.RandomFlip(模式=”水平”))
列车_ds=列车_ds.map(lambda图像,标签:(预处理模型(图像),标签))
val_ ds=构建_数据集(“验证”)
有效_大小=val _ ds.基数().numpy()
val_ds=val_ds.unbatch()批(批次_尺寸)
val_ ds=val_ ds.map(lambda图像,标签:(标准化_层(图像),标签))
输出:

定义模型
您所需要做的就是使用Hub模块将线姓分类器分层到特征提取器层之上。
我们最初使用未经训练的特征提取层来提高速度,但您也可以启用微调以获得更好的精度。
do _ fine _调谐=True
打印(“带”的建筑模型,模型_手柄)
模型=tf.keras.顺序(〔
#明确定义输入形状,以便模型能够正确
#由TFLiteConverter加载
tf.keras.layers.InputLayer(输入_形状=图像_尺寸+(3,))
hub.KerasLayer(型号_手柄)
tf.keras.layers.Dropout(速率=0.2)
tf.keras.layers.Dense(len(类名称),活化=”sigmoid”
核_正则化器=tf.keras.regularizers.l2(0.0001))
])
model.build((无,)+图像_尺寸+(3,))
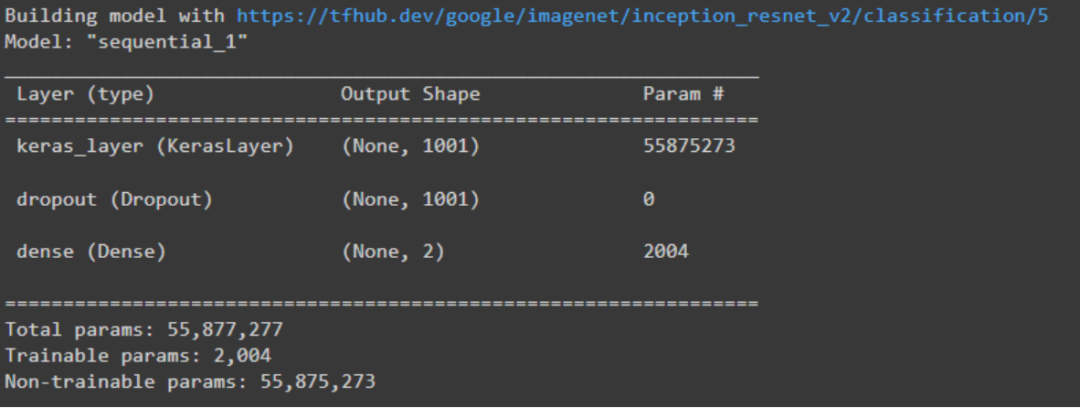
模型.summary()
输出如下
模型训练
模型堆(
优化器=tf.keras.optimizers.SGD(学习速率=0.005,动量=0.9)
loss=tf.keras.losses.CategoricalCrossentropy(来自_logits=True,标签_smoothing=0.1)
度量=〔”精度”〕)
步数_每_纪元=列车_尺寸//批次_尺寸
验证_步骤=有效_尺寸//批次_尺寸
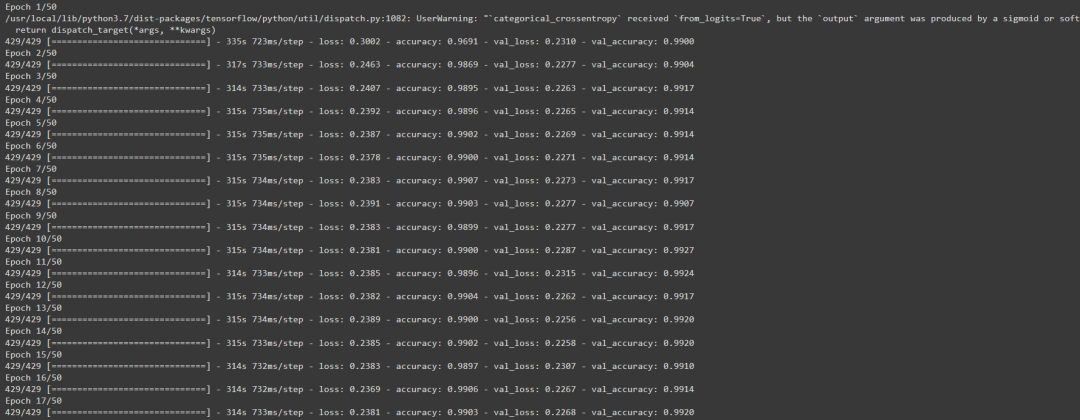
hist=模型拟合(
列车_ ds
epochs=50,步长_每_
验证_数据=val_ ds
验证步骤=验证步骤)。历史
输出如下:
培训结束后,我们需要用以下代码保存模型:
model.save(“保存位置modelname.h5”)
结论
这篇博客文章使用卷积神经网络(CNN)根据图片的视觉内容对图片进行分类。该数据集用于测试和训练CNN。准确率大于98%。我们必须使用微小的灰涩图像作为我们的教学资源。与其他常规JPEG照片相比,这些照片需要大量的处理时间。具有更多层和更多图像数据的模型用于在GPU集群上训练网络,将更准确地对图像进行分类。未来的发展将集中于对图像分割非常有用的巨大彩涩图像的分类。
关键点
·图像分类是计算机视觉的一个分支。它使用一组由算法训练的指定标签或类别对图像中的像素或向量集进行分类和标记。
·监督和非监督分类可以区分。
·在监督分类中,分类算法使用一组图像及其相关标签进行训练。
600学习网 » 使用 Google Colab 训练的图像分类模型-600学习网



